1.存储 #
当你已经完成了数据的加载和索引后,通常希望将其持久化存储,以避免每次都重新索引带来的时间和成本消耗。默认情况下,索引数据仅存储在内存中。
2.持久化到磁盘 #
存储索引数据最简单的方法是使用每个Index对象自带的 .persist() 方法,它会将所有数据写入到指定目录的磁盘中,适用于任何类型的索引。
# 将索引数据持久化保存到指定目录
# persist_dir参数指定保存的目录路径
index.storage_context.persist(persist_dir="<persist_dir>")之后,你可以像这样加载持久化的索引,避免重新加载和重新索引数据:
# 导入llama_index核心模块中的StorageContext、load_index_from_storage、VectorStoreIndex和Document类
from llama_index.core import (
StorageContext,
load_index_from_storage,
VectorStoreIndex,
Document,
)
# 构建一个包含三条示例文本的列表,用于后续演示
sample_texts = [
"LlamaIndex是一个强大的数据框架,用于构建LLM应用。",
"持久化存储可以避免重复计算嵌入向量,节省时间和成本。",
"通过存储索引,可以快速加载和重用已处理的数据。",
]
# 将每条文本包装成Document对象,便于后续索引处理
documents = [Document(text=text) for text in sample_texts]
# 基于文档列表创建向量索引
index = VectorStoreIndex.from_documents(documents)
# 将索引的存储上下文持久化到指定目录(./storage_demo)
index.storage_context.persist(persist_dir="./storage_demo")
# 打印提示信息,说明索引已保存到本地目录
print("✅ 索引已保存到 ./storage_demo 目录")
# 通过StorageContext的from_defaults方法,从指定目录重建存储上下文
storage_context = StorageContext.from_defaults(persist_dir="./storage_demo")
# 利用重建的存储上下文,从磁盘加载已持久化的向量索引
index = load_index_from_storage(storage_context)
# 打印提示信息,说明索引已成功从磁盘加载
print("✅ 索引已从磁盘加载")
# 通过加载的索引创建查询引擎
query_engine = index.as_query_engine()
# 使用查询引擎执行一次查询,问题为“什么是LlamaIndex?”
response = query_engine.query("什么是LlamaIndex?")
# 打印查询结果
print(f"查询结果: {response}")
提示:如果你在初始化索引时自定义了
transformations、embed_model等参数,后续加载时也需要传入相同的选项,或将其设置为全局设置。
3.使用向量存储 #
如索引章节所述,最常见的索引类型之一是 VectorStoreIndex。由于嵌入生成和索引操作可能在时间和金钱上成本高昂,因此建议将其存储下来,避免重复计算。
LlamaIndex 支持多种向量存储库,它们在架构、复杂性和成本上各不相同。这里以开源的Chroma为例:
3.1 安装Chroma #
# 安装ChromaDB,这是一个开源的向量数据库
# ChromaDB提供了高效的向量存储和检索功能
pip install chromadb
# 安装LlamaIndex的Chroma集成包
# 这个包提供了LlamaIndex与ChromaDB的集成接口
pip install llama-index-vector-stores-chroma3.2 使用Chroma存储嵌入向量 #
- 初始化Chroma客户端
- 在Chroma中创建Collection存储数据
- 将Chroma分配为
vector_store,并创建StorageContext - 使用该
StorageContext初始化VectorStoreIndex
# 导入chromadb库,用于操作Chroma向量数据库
import chromadb
# 从llama_index.core模块导入VectorStoreIndex和StorageContext类
from llama_index.core import VectorStoreIndex, StorageContext
# 从llama_index.vector_stores.chroma模块导入ChromaVectorStore类,实现与ChromaDB的集成
from llama_index.vector_stores.chroma import ChromaVectorStore
# 初始化Chroma的持久化客户端,数据将保存到指定目录"./chroma_db"
db = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"llamaindex_demo"的Collection,类似于数据库中的表
chroma_collection = db.get_or_create_collection("llamaindex_demo")
# 创建ChromaVectorStore实例,实现LlamaIndex与ChromaDB的对接
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 创建存储上下文对象,管理索引的存储配置(如向量存储)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 直接从向量存储加载索引,无需重新处理文档
index = VectorStoreIndex.from_vector_store(
vector_store, storage_context=storage_context
)
# 通过索引对象创建查询引擎
query_engine = index.as_query_engine()
# 测试查询,检索与"LlamaIndex的主要功能是什么?"相关的内容
response = query_engine.query("LlamaIndex的主要功能是什么?")
# 打印查询结果
print(f"查询结果: {response}")
# 打印索引加载成功的提示信息
print("✅ 已成功从ChromaDB加载索引")
3.3 直接加载已存储的嵌入向量 #
如果你已经创建并存储了嵌入向量,可以直接加载,无需重新加载文档或创建新索引:
# 导入必要的库
import chromadb
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.chroma import ChromaVectorStore
# 初始化Chroma客户端
# 使用与之前相同的路径,确保连接到同一个数据库
db = chromadb.PersistentClient(path="./chroma_db")
# 获取已存在的Collection
# 如果Collection不存在,get_or_create_collection会创建新的
chroma_collection = db.get_or_create_collection("llamaindex_demo")
# 创建ChromaVectorStore实例
# 这个实例会连接到指定的Collection
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 创建存储上下文
# 使用指定的向量存储创建存储上下文
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 从已存储的向量加载索引
# from_vector_store方法直接从向量存储创建索引,不需要重新处理文档
index = VectorStoreIndex.from_vector_store(
vector_store,
storage_context=storage_context
)
# 创建查询引擎
query_engine = index.as_query_engine()
# 执行查询测试
response = query_engine.query("LlamaIndex的主要功能是什么?")
print(f"查询结果: {response}")
print("✅ 已成功从ChromaDB加载索引")提示:我们有一个更详尽的Chroma使用示例,欢迎深入学习。
3.4 ChromaVectorStore #
ChromaVectorStore 中存储的不仅仅是向量,而是完整的索引数据,包括:
3.4.1. 嵌入向量(Embeddings) #
- 文档文本的向量化表示
- 用于语义搜索和相似度计算
- 这是向量存储的核心数据
3.4.2. 原始文本内容 #
- 文档的原始文本
- 用于检索时返回相关文本片段
- 与向量建立映射关系
3.4.3. 元数据(Metadata) #
- 文档的额外信息(如文件名、创建时间等)
- 节点的ID和类型信息
- 用于过滤和排序
3.4.4. 索引结构信息 #
- 节点之间的关系
- 文档分割信息
- 索引配置参数
3.4.5. 实际存储结构 #
当您使用 ChromaVectorStore 时,它会在 ChromaDB 中存储:
# ChromaDB 中实际存储的数据结构
{
"ids": ["node_1", "node_2", "node_3"],
"embeddings": [[0.1, 0.2, ...], [0.3, 0.4, ...], ...], # 向量
"documents": ["文本内容1", "文本内容2", "文本内容3"], # 原始文本
"metadatas": [{"source": "file1.md"}, {"source": "file2.md"}, ...] # 元数据
}4.插入Documents或Nodes #
如果你已经创建了一个索引,可以使用 insert 方法向索引中添加新文档:
# 导入llama_index.core中的VectorStoreIndex和Document类
from llama_index.core import VectorStoreIndex, Document
# 定义初始文档内容的列表
initial_texts = [
"LlamaIndex支持动态插入新文档。",
"通过insert方法,可以向现有索引添加新的文档。",
]
# 将初始文本内容转换为Document对象列表
initial_documents = [Document(text=text) for text in initial_texts]
# 创建一个空的向量索引对象
index = VectorStoreIndex([])
# 遍历初始文档列表,逐个插入到索引中
for doc in initial_documents:
# 打印正在插入的文档内容(最多显示前50个字符)
print(f"正在插入文档: {doc.text[:50]}...")
# 调用insert方法将文档插入索引
index.insert(doc)
# 通过索引对象创建查询引擎
query_engine = index.as_query_engine()
# 使用查询引擎进行一次查询,问题为“如何向索引添加新文档?”
response = query_engine.query("如何向索引添加新文档?")
# 打印查询结果
print(f"查询结果: {response}")
# 定义需要追加的新文档内容列表
additional_texts = [
"动态插入功能使得索引可以不断更新和扩展。",
"这对于处理实时数据或增量更新非常有用。",
]
# 将追加文本内容转换为Document对象列表
additional_documents = [Document(text=text) for text in additional_texts]
# 遍历追加文档列表,逐个插入到现有索引中
for doc in additional_documents:
# 打印正在插入的新文档内容(最多显示前50个字符)
print(f"正在插入新文档: {doc.text[:50]}...")
# 调用insert方法将新文档插入索引
index.insert(doc)
# 再次使用查询引擎进行查询,问题为“动态插入有什么好处?”
response = query_engine.query("动态插入有什么好处?")
# 打印更新后的查询结果
print(f"更新后的查询结果: {response}")
更多文档管理操作和示例,请参阅文档管理操作指南。
5.高级存储示例 #
5.1 使用Pinecone向量数据库 #
uv add llama-index-vector-stores-pinecone pinecone-client- llama-index-vector-stores-pinecone:Pinecone向量存储的集成包
- pinecone-client:Pinecone云向量数据库客户端
# 导入llama_index核心模块中的VectorStoreIndex、Document和StorageContext类
from llama_index.core import VectorStoreIndex, Document, StorageContext
# 从llama_index的pinecone向量存储模块导入PineconeVectorStore类
from llama_index.vector_stores.pinecone import PineconeVectorStore
# 从pinecone库导入Pinecone和ServerlessSpec类
from pinecone import Pinecone, ServerlessSpec
# 初始化Pinecone对象,使用新的API格式,并传入API密钥
pc = Pinecone(
api_key="pcsk_62ZrTU_Mmd8isarnWjT4ZhupFnKyZZm1rxsfZuNXcQNvHPhh7TzH1xsak43KQQHKSPqds"
)
# 定义Pinecone索引名称
index_name = "llamaindex-demo"
# 如果该索引名称不存在于Pinecone当前的索引列表中,则创建新索引
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=1536, # 指定OpenAI嵌入向量的维度为1536
metric="cosine", # 使用余弦相似度作为度量方式
spec=ServerlessSpec(cloud="aws", region="us-east-1"), # 指定云服务和区域
)
# 连接到已创建或已存在的Pinecone索引
pinecone_index = pc.Index(index_name)
# 基于Pinecone索引创建PineconeVectorStore对象
vector_store = PineconeVectorStore(pinecone_index=pinecone_index)
# 创建存储上下文对象,并将vector_store作为默认向量存储
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 构建示例文本列表,作为待存储的文档内容
sample_texts = [
"Pinecone是一个云端的向量数据库,提供高性能的向量存储和检索。",
"通过Pinecone,可以实现大规模向量数据的存储和快速检索。",
"Pinecone支持实时更新和复杂的向量查询操作。",
]
# 将每个示例文本包装为Document对象,生成文档列表
documents = [Document(text=text) for text in sample_texts]
# 从文档列表创建向量索引,指定存储上下文,并显示进度条
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, show_progress=True
)
# 获取查询引擎对象
query_engine = index.as_query_engine()
# 使用查询引擎对问题进行检索
response = query_engine.query("Pinecone是什么?")
# 打印查询结果
print(f"查询结果: {response}")
5.2 使用Weaviate向量数据库 #
uv add llama-index-vector-stores-weaviate weaviate-client- llama-index-vector-stores-weaviate:Weaviate向量存储的集成包
- weaviate-client:Weaviate向量数据库客户端
# 导入VectorStoreIndex、Document和StorageContext类,用于向量存储和文档管理
from llama_index.core import VectorStoreIndex, Document, StorageContext
# 导入WeaviateVectorStore类,用于对接Weaviate向量数据库
from llama_index.vector_stores.weaviate import WeaviateVectorStore
# 导入weaviate库,用于连接Weaviate云服务
import weaviate
# 导入Auth类,用于API密钥认证
from weaviate.classes.init import Auth
# 定义Weaviate云端服务的URL地址
weaviate_url = "boxrqyhdqwwfrsjsgdcfg.c0.asia-southeast1.gcp.weaviate.cloud"
# 定义Weaviate云端服务的API密钥
weaviate_api_key = "UHFySVoxOXJXRUljb3dUZV9WME1ySTdIZ3prRkRucTYvN0dWclNDNXZ1VkVzcGgyVGZVUTFTcmJTeUFnPV92MjAw"
# 通过API密钥认证并连接到Weaviate云端服务
client = weaviate.connect_to_weaviate_cloud(
cluster_url=weaviate_url,
auth_credentials=Auth.api_key(weaviate_api_key),
)
# 创建WeaviateVectorStore对象,指定索引名称和客户端连接
vector_store = WeaviateVectorStore(weaviate_client=client, index_name="LlamaIndexDemo")
# 创建存储上下文对象,绑定向量存储
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 构建示例文本列表
sample_texts = [
"Weaviate是一个开源的向量数据库,支持多种数据类型。",
"Weaviate提供了GraphQL API,便于集成和查询。",
"Weaviate支持语义搜索和结构化数据查询。",
]
# 将每个示例文本封装为Document对象
documents = [Document(text=text) for text in sample_texts]
# 从文档列表创建向量索引,指定存储上下文,并显示进度条
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, show_progress=True
)
# 获取查询引擎对象
query_engine = index.as_query_engine()
# 使用查询引擎进行问题检索
response = query_engine.query("Weaviate的优势是什么?")
# 打印查询结果
print(f"查询结果: {response}")
6.存储策略对比 #
| 存储方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 磁盘持久化 | 简单易用,免费 | 查询速度较慢 | 开发测试,小规模应用 |
| ChromaDB | 开源,本地部署 | 需要额外安装 | 本地开发,中等规模 |
| Pinecone | 云端,高性能 | 需要付费 | 生产环境,大规模应用 |
| Weaviate | 功能丰富,开源 | 配置复杂 | 企业级应用,复杂查询 |
7.最佳实践 #
7.1 选择合适的存储方案 #
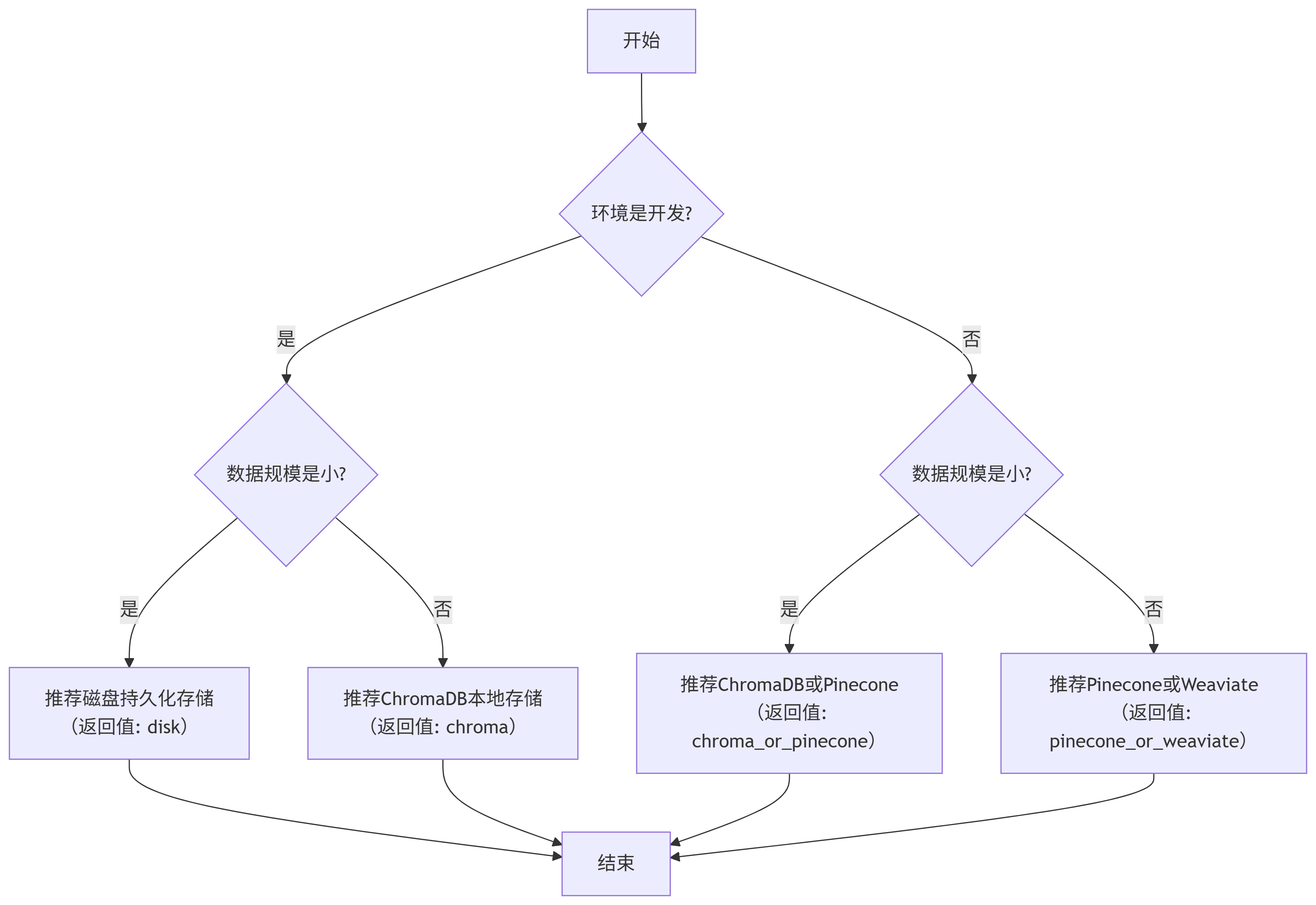
# 定义一个函数,根据数据规模和运行环境选择合适的存储策略
def choose_storage_strategy(data_size, environment):
"""
根据数据规模和运行环境选择合适的存储策略
Args:
data_size: 数据规模(小/中/大)
environment: 运行环境(开发/生产)
"""
# 如果是开发环境且数据规模为小
if environment == "开发" and data_size == "小":
# 输出推荐使用磁盘持久化存储
print("推荐使用磁盘持久化存储")
# 返回'disk'表示磁盘存储
return "disk"
# 如果是开发环境且数据规模为中或大
elif environment == "开发" and data_size in ["中", "大"]:
# 输出推荐使用ChromaDB本地存储
print("推荐使用ChromaDB本地存储")
# 返回'chroma'表示ChromaDB存储
return "chroma"
# 如果是生产环境且数据规模为小
elif environment == "生产" and data_size == "小":
# 输出推荐使用ChromaDB或Pinecone
print("推荐使用ChromaDB或Pinecone")
# 返回'chroma_or_pinecone'表示ChromaDB或Pinecone存储
return "chroma_or_pinecone"
# 如果是生产环境且数据规模为中或大
elif environment == "生产" and data_size in ["中", "大"]:
# 输出推荐使用Pinecone或Weaviate
print("推荐使用Pinecone或Weaviate")
# 返回'pinecone_or_weaviate'表示Pinecone或Weaviate存储
return "pinecone_or_weaviate"
# 示例:调用choose_storage_strategy函数,传入数据规模为“中”,环境为“开发”
strategy = choose_storage_strategy("中", "开发")
# 输出选择的存储策略
print(f"选择的存储策略: {strategy}")
| 数据规模 | 运行环境 | 推荐存储策略 | 返回值 |
|---|---|---|---|
| 小 | 开发 | 磁盘持久化存储 | "disk" |
| 中 / 大 | 开发 | ChromaDB本地存储 | "chroma" |
| 小 | 生产 | ChromaDB 或 Pinecone | "chroma_or_pinecone" |
| 中 / 大 | 生产 | Pinecone 或 Weaviate | "pinecone_or_weaviate" |
7.2 数据备份和恢复 #
# 导入llama_index核心模块中的所需类和方法
from llama_index.core import (
VectorStoreIndex, # 向量存储索引类
Document, # 文档对象类
StorageContext, # 存储上下文类
load_index_from_storage, # 从存储中加载索引的方法
)
# 导入shutil库,用于文件和目录的高级操作
import shutil
# 导入os库,用于操作系统相关功能
import os
# 构建示例文本列表,用于创建索引
sample_texts = [
"数据备份是确保数据安全的重要措施。",
"定期备份可以防止数据丢失和损坏。",
"备份策略应该根据数据重要性制定。",
]
# 将每条示例文本封装为Document对象
documents = [Document(text=text) for text in sample_texts]
# 从文档对象列表创建向量索引
index = VectorStoreIndex.from_documents(documents)
# 将索引持久化保存到指定目录(原始存储目录)
index.storage_context.persist(persist_dir="./original_storage")
# 输出原始索引创建成功的信息
print("✅ 原始索引已创建")
# 指定备份存储目录
backup_dir = "./backup_storage"
# 如果备份目录已存在,则先删除
if os.path.exists(backup_dir):
shutil.rmtree(backup_dir) # 删除已存在的备份目录
# 复制原始存储目录到备份目录,实现索引数据备份
shutil.copytree("./original_storage", backup_dir)
# 输出索引备份成功的信息
print("✅ 索引已备份到 ./backup_storage")
# 删除原始存储目录,模拟数据丢失场景
shutil.rmtree("./original_storage")
# 输出模拟数据丢失的提示
print("⚠️ 原始数据已删除(模拟数据丢失)")
# 从备份目录创建存储上下文对象
storage_context = StorageContext.from_defaults(persist_dir=backup_dir)
# 从存储上下文中加载恢复索引
restored_index = load_index_from_storage(storage_context)
# 输出索引恢复成功的信息
print("✅ 索引已从备份恢复")
# 获取恢复索引的查询引擎w
query_engine = restored_index.as_query_engine()
# 使用查询引擎进行问题检索
response = query_engine.query("为什么需要数据备份?")
# 打印查询结果
print(f"查询结果: {response}")
8.总结 #
- 持久化存储:通过
.persist()方法将索引数据保存到磁盘,避免重复索引。 - 向量存储集成:支持多种向量数据库,推荐使用Chroma等高效存储方案。
- 灵活加载与插入:支持从磁盘、向量存储加载索引,并可动态插入新文档。
- 存储策略选择:根据数据规模和运行环境选择合适的存储方案。
- 数据安全:实施定期备份策略,确保数据安全。
掌握索引的存储与管理,将极大提升RAG应用的效率和可维护性。
9.安装指南 #
在运行上述代码之前,您需要安装必要的包:
# 安装LlamaIndex核心包
pip install llama-index
# 安装ChromaDB集成(用于本地向量存储)
pip install llama-index-vector-stores-chroma
pip install chromadb
# 安装Pinecone集成(用于云端向量存储)
pip install llama-index-vector-stores-pinecone
pip install pinecone-client
# 安装Weaviate集成(用于企业级向量存储)
pip install llama-index-vector-stores-weaviate
pip install weaviate-client包说明: #
- llama-index:LlamaIndex的核心包,包含所有基本的索引和查询功能
- llama-index-vector-stores-chroma:ChromaDB向量存储的集成包
- chromadb:ChromaDB向量数据库客户端
- llama-index-vector-stores-pinecone:Pinecone向量存储的集成包
- pinecone-client:Pinecone云向量数据库客户端
- llama-index-vector-stores-weaviate:Weaviate向量存储的集成包
- weaviate-client:Weaviate向量数据库客户端
环境变量设置: #
如果您使用Pinecone,需要设置API密钥:
import os
# 设置Pinecone API密钥和环境
os.environ["PINECONE_API_KEY"] = "your-pinecone-api-key"
os.environ["PINECONE_ENVIRONMENT"] = "your-pinecone-environment"请将 your-pinecone-api-key 和 your-pinecone-environment 替换为您的实际Pinecone配置。