1. 什么是RAG? #
大型语言模型(LLMs)基于海量数据进行训练,但并未针对您的数据进行优化。检索增强生成(RAG)通过将您的数据添加到LLM已有的访问数据中来解决这个问题。您将在本文档中频繁看到RAG的提及。查询引擎、聊天引擎和代理通常使用RAG来完成它们的任务。
在RAG中,您的数据会被加载并准备好进行查询或"索引"。用户查询作用于该索引,将数据筛选至最相关的上下文。随后,该上下文与您的查询会连同提示一起发送给LLM,由LLM生成响应。
即便您正在构建的是聊天机器人或智能代理,也需要掌握RAG技术来实现数据导入应用。
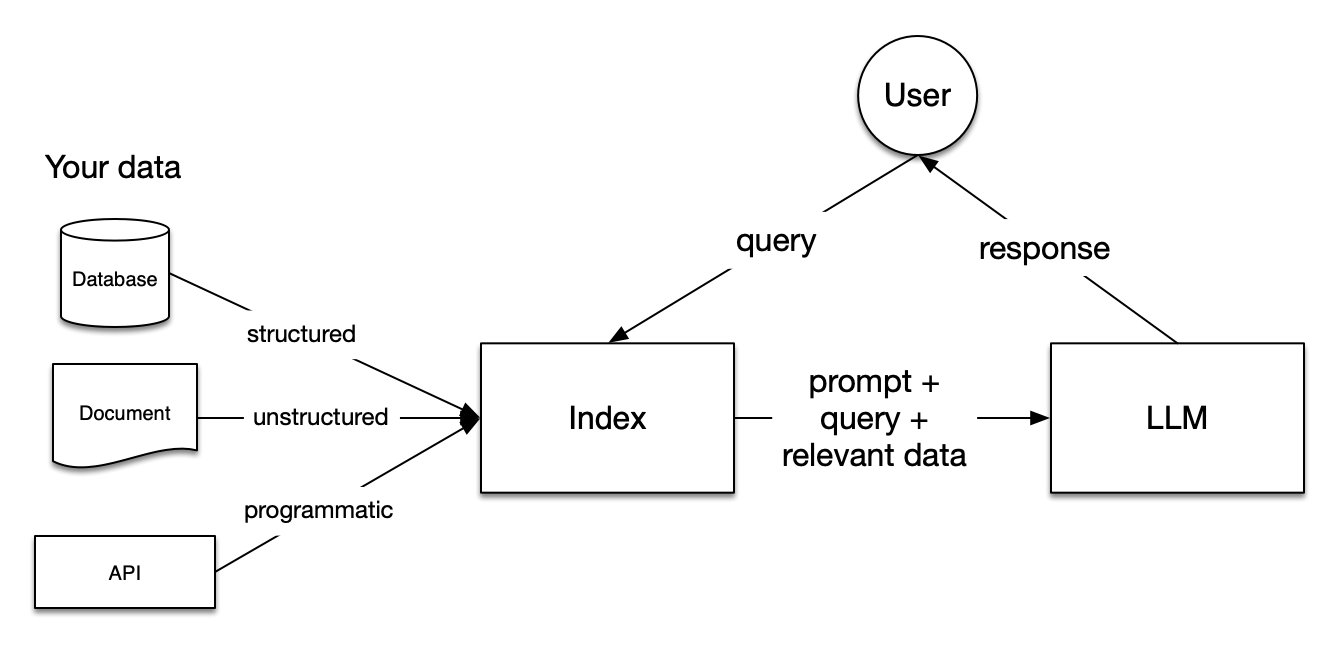
这是一个典型的检索增强生成(RAG)系统架构图,展示了如何将用户查询与数据源结合,通过LLM生成智能回答。
1.1 核心组件 #
1.1.1 数据源(左侧) #
系统支持三种类型的数据输入:
数据库(Database):提供结构化数据
- 如SQL数据库、NoSQL数据库等
- 数据格式规范,便于查询和处理
文档(Document):提供非结构化数据
- 如PDF文件、Word文档、文本文件等
- 需要解析和提取才能使用
API:提供程序化数据
- 如REST API、GraphQL接口等
- 实时获取外部数据
1.1.2 索引(Index)- 核心处理中心 #
索引是整个系统的核心组件,负责:
- 数据整合:接收来自不同数据源的信息
- 查询处理:接收用户查询并理解意图
- 相关性检索:根据查询从数据源中检索相关信息
- 上下文构建:将查询、提示词和相关数据组合
1.1.3 大语言模型(LLM)- 智能生成器 #
LLM接收来自索引的丰富上下文,包括:
- 提示词(prompt):指导模型如何回答
- 查询(query):用户的具体问题
- 相关数据(relevant data):从数据源检索到的相关信息
1.2 工作流程 #
- 用户发起查询:用户向系统提出问题
- 索引处理:索引接收查询,从各种数据源检索相关信息
- 上下文构建:索引将查询、提示词和相关数据组合成完整的上下文
- LLM生成:LLM基于完整上下文生成智能回答
- 返回结果:将生成的回答返回给用户
1.3 技术优势 #
这种架构的优势在于:
- 数据融合:能够同时处理结构化和非结构化数据
- 智能检索:只获取与查询相关的数据,提高效率
- 上下文增强:为LLM提供丰富的背景信息
- 可扩展性:可以轻松添加新的数据源和模型
1.4 实际应用场景 #
这种架构特别适用于:
- 企业知识库问答系统
- 文档智能助手
- 多源数据查询平台
- 个性化推荐系统
3. RAG 中的五个关键阶段 #
RAG流程包含五个关键阶段,这些阶段将构成您所构建的大多数大型应用程序的核心部分:

3.1 加载阶段 #
这指的是将数据从其原始位置(无论是文本文件、PDF、其他网站、数据库还是API)导入到您的工作流程中。LlamaHub提供数百种连接器供选择。
3.2 索引阶段 #
这意味着构建一种数据结构以便查询数据。对于LLMs而言,这几乎总是需要创建 vector embeddings(数据含义的数值化表示),以及众多其他元数据策略,旨在轻松准确地找到上下文相关的数据。
3.3 存储阶段 #
一旦您的数据被索引,通常您会希望存储索引及其他元数据,以避免重新索引。
3.4 查询阶段 #
对于任何给定的索引策略,您都可以通过多种方式利用LLMs和LlamaIndex数据结构进行查询,包括子查询、多步查询以及混合策略。
3.5 评估阶段 #
在任何流程中,关键一步都是检查其相对于其他策略的有效性,或在做出更改时进行评估。评估能提供客观指标,衡量您对查询的响应有多准确、可靠和快速。
4. RAG中的关键概念 #
在每个阶段中,您还会遇到一些指代具体步骤的术语。以下是各阶段的核心概念:
4.1 加载阶段的关键概念 #
4.1.1 节点与文档 #
一个 Document 是一个围绕任何数据源的容器——例如,一个PDF、API输出或从数据库检索的数据。Node 是LlamaIndex中的基本数据单元,代表源数据的"块"。Document 节点拥有元数据,这些元数据将它们与所属文档及其他节点关联起来。
4.1.2 连接器 #
数据连接器(通常称为 Reader)从不同数据源和数据格式中摄取数据到 Documents 和 Nodes。
4.2 索引阶段的关键概念 #
4.2.1 索引 #
一旦您导入了数据,LlamaIndex将帮助您将这些数据索引化为易于检索的结构。这一过程通常涉及生成 vector embeddings,它们存储在一个名为 vector store 的专用数据库中。索引还可以存储关于数据的各种元数据。
4.2.2 嵌入 #
LLMs生成的数据数值表示称为 embeddings。在筛选数据相关性时,LlamaIndex会将查询转换为嵌入向量,而您的向量存储会查找与查询嵌入向量数值相似的数据。
4.3 查询阶段的关键概念 #
4.3.1 检索器 #
检索器定义了在给定查询时如何高效地从索引中获取相关上下文。您的检索策略对于所获取数据的相关性及执行效率至关重要。
4.3.2 路由器 #
路由器决定将使用哪个检索器从知识库中检索相关上下文。更具体地说,RouterRetriever 类负责选择一个或多个候选检索器来执行查询。它们通过选择器根据每个候选的元数据和查询内容来挑选最佳选项。
4.3.3 节点后处理器 #
一个节点后处理器接收一组检索到的节点,并对它们应用转换、过滤或重新排序的逻辑。
4.3.4 响应合成器 #
响应合成器利用用户查询和一组给定的检索文本块,通过LLM生成回应。
5. 总结 #
RAG技术是现代AI应用的核心,它通过以下方式增强LLM的能力:
- 个性化:让LLM能够访问您的特定数据
- 准确性:通过检索相关上下文提高回答质量
- 可扩展性:支持处理大量文档和数据源
- 灵活性:适应各种数据格式和查询需求
掌握RAG的五个阶段和关键概念,将帮助您构建更强大、更智能的AI应用程序。